
Más de la mitad del tráfico diario de Internet está generado de forma automática por bots donde no intervienen los humanos en ningún punto (más allá de la creación del bot, claro). Esto nos da una idea de la cantidad de robots que cada día hacen operaciones en la red.
En el caso de las páginas web existe un archivo pensado para darle unas pautas de lo que deben ver y registrar y de lo que no. Hablo del archivo robots.txt, un archivo de texto con extensión .txt que todas las webs deberían tener en su carpeta raíz y que sirve de “guía” para los robots.
Pero antes de entrar en más detalle a hablar sobre el robots.txt, creo que es importante explicar a qué tipo de bots afecta. En concreto, este archivo afecta principalmente a los robots de los buscadores, también conocidos como spyders, crawlers o arañas.

Estas arañas se ocupan de ir recorriendo todas las páginas webs y leyendo su contenido, para que posteriormente los buscadores como Google o Bing puedan categorizarlos e incluirlos en su índice. Gracias a esto, cuando hacemos una búsqueda, puede darnos como resultado prácticamente cualquier página de Internet.
El caso de los robots de los buscadores es el más importante y para el que realmente fue diseñado el archivo robots.txt, pero hay más arañas recorriendo Internet. Por ejemplo, muchas herramientas de optimización web tienen sus propias arañas y en muchos casos respetan las directrices del archivo robots.txt, aunque es cierto que en algunos casos es posible configurar estas herramientas para que los ignoren completamente.
¿Qué es y qué hace el archivo robots.txt?
Al crear una nueva web, es necesario que Google y otros buscadores puedan acceder a la web para rastrar la información. Para ello, se requiere crear un nuevo archivo de texto con extensión .txt en el dominio para dar al buscador la información que necesita para saber de la web o negocio. Este archivo se usa para impedir que los bots añaden datos que no se quieren compartir. Este archivo se encuentra en la raíz del sitio indicando lo que quieres que rastreen o no los motores de búsqueda.
Como decía, el archivo robots.txt se encarga de dar una serie de directrices a los robots de buscadores y otras herramientas. Básicamente estas directrices se limitan a indicar qué partes de la web no debe indexar para que aparezcan en los buscadores o de qué partes no debe extraer información.
Gracias a esto, es posible evitar que ciertas URLs, directorios completos o incluso archivos determinados aparezcan en los buscadores. También, es posible utilizar el archivo para hacer que los robots naveguen de una forma un poco más lenta por la web e incluso indicarles dónde está el archivo sitemap.xml con todas las URLs que sí debe indexar.
Es importante mencionar que las reglas establecidas en el robots.txt no siempre son respetadas. Se trata de unas directrices, pero en determinados casos los bots pueden decidir saltárselas por cualquier motivo (bueno, más bien es el creador del bot el que decide esto).
Es por esto que no es aconsejable utilizar el robots.txt para proteger zonas privadas de una web, ya que podrían acabar indexadas igualmente, lo que facilitaría que cualquier persona pueda llegar a la información que en ella se muestre. En este caso, mejor utilizar un acceso restringido por contraseña, por IP o similar.
¿Cómo crear el archivo robots.txt?
Para crear el archivo robots.txt de cualquier página web solo necesitas tener acceso al directorio raíz del hosting en el que está alojada la página web y en él crear un archivo de texto plano llamado robots.txt. No uses un procesador de texto para ello, sino algún editor de textos como el Bloc de Notas.
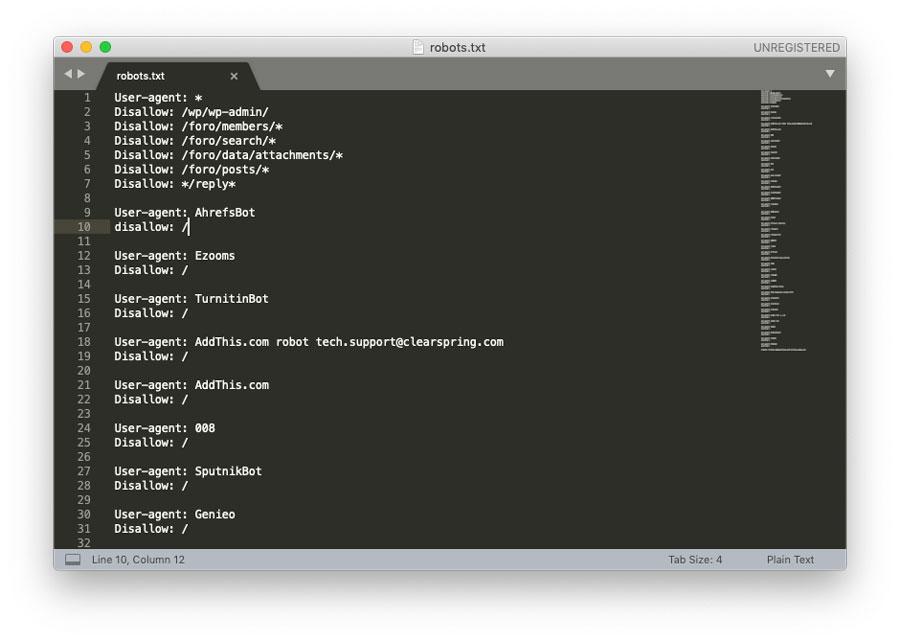
Una vez creado el archivo debes editarlo e introducir las reglas que necesites definir siguiendo la sintaxis adecuada para este tipo de archivos.
Los comandos más importantes a la hora de generar un archivo de este tipo son los siguientes:
- User-agent: nombrebot – establece el inicio de una orden para un bot determinado.
- User-agent: * – establece el inicio de una orden para todos los bots.
- Disallow: / – bloquea el acceso a toda la web.
- Disallow: /directorio/ – bloquea el acceso a un determinado directorio y a todo el contenido que incluya.
- Disallow: /url.html – bloquea el acceso a una determinada URL.
- Allow: /directorio/ – permite el acceso a un determinado directorio.
- Crawl-delay: 3600 – establece un tiempo determinado de cada cuánto debe pasarse un robot por el sitio. El tiempo debe expresarse en segundos.
Además, también puedes utilizar concordancia mediante patrones a la hora de crear tu robots.txt. Las opciones disponibles son las siguientes:
- Asterisco (*) : se utiliza como comodín, si lo pones después de una serie de caracteres incluirá todas las URLs que incluyan esos caracteres en la misma posición. Por ejemplo, si en una regla incluyes /private*/ hará referencia a todos los subdirectorios que empiecen por la palabra private y que después tenga cualquier otra secuencia.
- Interrogación (?): puedes utilizar este símbolo para indicar el final de una URL. Por ejemplo /.xls$ hará referencia a todas las URLs que terminen el .xls
- Símbolo del dólar ($): bloquea URLs que terminen de una forma determinada. Por ejemplo, si quieres bloquear todas las URLs acabadas en .php lo harías con /*.php$.
La forma de subir el archivo dependerá de la estructura de tu web y del servidor. Puedes FTP para ello con algún programa cliente como Filezilla, o subirlo por cPanel, aunque dependerá de cómo funcione tu servicio de alojamiento. Como tendrá que estar en la raíz, debes buscar htdocs o public_html, Para comprobar si el archivo creado y subido es de acceso público, abre una ventana privada en tu navegador y ve hasta su ubicación. Si ves el contenido, ya puedes probarlo. Puedes usar el Probador de robots.txt de Search Console para ello. Una vez que hayas subido y probado tu archivo robots.txt, los rastreadores lo buscarán y empezarán a usar automáticamente sin que tengas que hacer nada más.
Si quieres tener más información sobre la creación y las reglas de este archivo, podrás saber mucho más en la web de Google, en que te da mucha información interesante para que lo hagas bien siguiendo sus directrices. Por eso, si quieres saber más consulta esta página.